Ever wondered what’s really happening under the hood of your computer or server? A system monitor can tell you—down to the last byte. Discover how real-time insights boost efficiency, prevent crashes, and secure your digital ecosystem.





What Is a System Monitor and Why It Matters

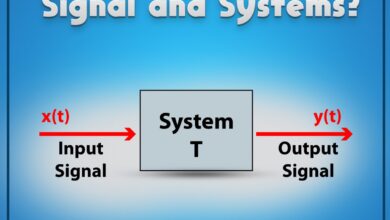
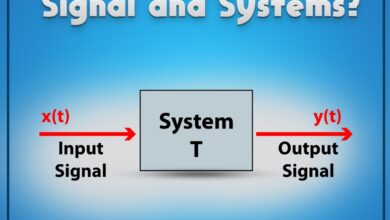
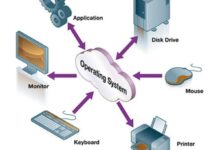
A system monitor is more than just a dashboard of numbers—it’s the central nervous system for your IT infrastructure. Whether you’re managing a single workstation or a sprawling cloud network, continuous monitoring ensures everything runs smoothly, securely, and efficiently. At its core, a system monitor tracks key performance indicators like CPU usage, memory consumption, disk I/O, network activity, and application health.
Core Functions of a System Monitor
The primary role of a system monitor is to collect, analyze, and report on system metrics in real time. This enables administrators to detect anomalies before they escalate into outages. For example, if a server’s memory usage spikes unexpectedly, a system monitor can trigger an alert, allowing IT teams to investigate and resolve the issue before users are affected.
- Real-time data collection from hardware and software components
- Automated alerting based on predefined thresholds
- Historical data logging for trend analysis and capacity planning
Modern system monitors go beyond basic metrics. They integrate with application performance management (APM) tools, log analyzers, and security information and event management (SIEM) systems to provide a holistic view of the IT environment. This integration is essential in today’s complex, hybrid infrastructures where workloads span on-premises servers, virtual machines, containers, and public clouds.
“Monitoring is not about collecting data—it’s about turning data into decisions.” — Unknown DevOps Engineer
Types of System Monitoring
Not all monitoring is created equal. Depending on the environment and objectives, organizations deploy different types of system monitoring. These include infrastructure monitoring, application performance monitoring (APM), network monitoring, and log monitoring.
- Infrastructure Monitoring: Focuses on hardware and OS-level metrics such as CPU, RAM, disk space, and uptime.
- Application Monitoring: Tracks the performance and availability of software applications, including response times and error rates.
- Network Monitoring: Observes traffic flow, bandwidth usage, latency, and packet loss across network devices.
Each type serves a unique purpose, but the most effective monitoring strategies combine multiple approaches. For instance, a sudden increase in network latency might not be a network issue at all—it could stem from a CPU bottleneck on a backend server. Only a comprehensive system monitor can correlate these events and pinpoint the root cause.
Top 7 System Monitor Tools in 2024
Choosing the right system monitor tool can make or break your IT operations. With dozens of options available, it’s crucial to evaluate features, scalability, ease of use, and integration capabilities. Below are seven of the most powerful and widely adopted system monitor solutions in 2024.
1. Nagios XI
Nagios XI remains a cornerstone in the world of system monitoring. Originally developed as an open-source project, Nagios has evolved into a robust enterprise-grade solution. It excels at monitoring servers, switches, applications, and services across hybrid environments.
- Supports thousands of plugins for custom monitoring
- Offers real-time alerting via email, SMS, and mobile apps
- Provides detailed dashboards and reporting tools
Nagios XI is particularly popular among organizations that require deep customization. Its plugin architecture allows users to monitor virtually any service or device, from legacy mainframes to modern microservices. However, its steep learning curve and complex configuration can be daunting for beginners. For more information, visit the official Nagios website.
2. Zabbix
Zabbix is a powerful open-source system monitor that combines scalability with enterprise features. It’s designed for large-scale deployments and can handle tens of thousands of devices with ease.
- Auto-discovery of network devices and services
- Advanced templating system for consistent configuration
- Built-in visualization tools and customizable dashboards
One of Zabbix’s standout features is its distributed monitoring capability, allowing organizations to deploy proxies in remote locations and centralize data collection. This makes it ideal for global enterprises with multiple data centers. Zabbix also supports machine learning-based anomaly detection, helping predict issues before they occur. Learn more at zabbix.com.
3. Datadog
Datadog is a cloud-native system monitor that has gained massive popularity among DevOps teams. It offers seamless integration with AWS, Azure, Google Cloud, Kubernetes, and hundreds of third-party services.
- Real-time infrastructure and application monitoring
- AI-powered anomaly detection and forecasting
- Collaboration features like shared dashboards and incident management
Datadog’s strength lies in its unified platform approach. Instead of juggling multiple tools, teams can monitor infrastructure, logs, traces, and user experience in one place. Its intuitive interface and powerful API make it a favorite for startups and enterprises alike. Explore Datadog at datadoghq.com.
4. Prometheus
Prometheus is an open-source monitoring and alerting toolkit originally developed at SoundCloud. It’s now a graduated project under the Cloud Native Computing Foundation (CNCF) and is widely used in containerized environments.
- Pull-based monitoring model using HTTP
- Powerful query language (PromQL) for data analysis
- Excellent integration with Kubernetes and Docker
Prometheus is particularly well-suited for dynamic, ephemeral workloads. It scrapes metrics from targets at regular intervals and stores them in a time-series database. While it lacks built-in visualization, it pairs perfectly with Grafana for stunning dashboards. Check out prometheus.io for documentation and downloads.
5. SolarWinds Server & Application Monitor (SAM)
SolarWinds SAM is a comprehensive system monitor designed for IT professionals who need deep visibility into both servers and applications.
- Pre-built templates for monitoring databases, web servers, and custom apps
- Root cause analysis and performance advisor tools
- Integration with SolarWinds Orion platform for unified management
SAM stands out for its ease of deployment and rich out-of-the-box monitoring capabilities. It supports Windows, Linux, and Unix systems, and can monitor everything from SQL Server performance to Apache response times. However, some users have raised concerns about pricing and scalability. Visit SolarWinds SAM for a free trial.
6. PRTG Network Monitor
Paessler PRTG is a Windows-based system monitor that offers a sensor-based approach to monitoring. Each sensor represents a specific metric, such as CPU load, bandwidth usage, or HTTP response time.
- Auto-discovery of network devices and services
- Over 200 sensor types for diverse monitoring needs
- Mobile app for on-the-go monitoring
PRTG is known for its user-friendly interface and rapid setup. It’s ideal for small to medium-sized businesses that need a reliable monitoring solution without the complexity of enterprise tools. The free version supports up to 100 sensors, making it a great choice for testing. Learn more at paessler.com.
7. New Relic
New Relic is a full-stack observability platform that goes beyond traditional system monitoring. It provides deep insights into applications, infrastructure, and user experiences.
- Distributed tracing for microservices
- Real user monitoring (RUM) to track end-user performance
- AI-driven insights and automated root cause detection
New Relic’s strength lies in its ability to connect infrastructure metrics with application performance and business outcomes. For example, it can show how a database slowdown affects customer checkout times on an e-commerce site. This holistic view is invaluable for modern digital businesses. Explore New Relic at newrelic.com.
Key Features to Look for in a System Monitor
Not all system monitor tools are created equal. To choose the right one for your organization, you need to evaluate several critical features. These include scalability, real-time alerting, ease of integration, and user interface design.
Real-Time Monitoring and Alerting
One of the most essential features of any system monitor is the ability to provide real-time visibility into system performance. Delays in detecting issues can lead to prolonged outages and lost revenue. A good system monitor should offer sub-minute data collection intervals and instant alerting via multiple channels—email, SMS, Slack, or mobile push notifications.
- Configurable thresholds for CPU, memory, disk, and network usage
- Escalation policies to ensure alerts reach the right person
- Silencing options during maintenance windows
For example, if a database server’s disk space drops below 10%, the system monitor should trigger an alert immediately. This allows administrators to take preventive action before the disk fills up and the database crashes.
Scalability and Performance
As your IT environment grows, your system monitor must scale with it. Whether you’re adding new servers, expanding to the cloud, or deploying containerized applications, the monitoring solution should handle increased data volume without performance degradation.
- Support for distributed architectures and monitoring proxies
- Efficient data storage and retrieval mechanisms
- Ability to monitor thousands of nodes simultaneously
Zabbix and Prometheus, for instance, are known for their scalability in large environments. They use efficient data compression and indexing to maintain performance even with massive datasets.
Integration and API Support
In today’s interconnected IT landscape, a system monitor must integrate seamlessly with other tools. This includes ticketing systems (like Jira), collaboration platforms (like Slack), CI/CD pipelines, and cloud services.
- RESTful APIs for custom integrations
- Pre-built connectors for popular platforms
- Webhook support for event-driven automation
For example, when a system monitor detects a server outage, it can automatically create a ticket in ServiceNow or send a message to a Slack channel. This reduces response time and improves incident management workflows.
How System Monitor Enhances IT Security
While system monitoring is often associated with performance and availability, it plays a crucial role in cybersecurity as well. By continuously observing system behavior, a system monitor can detect signs of compromise, such as unusual login attempts, unexpected process executions, or abnormal network traffic.
Threat Detection Through Anomaly Monitoring
Modern system monitors use behavioral analytics and machine learning to establish baselines of normal activity. When deviations occur—like a sudden spike in outbound traffic or a process consuming excessive CPU—they can flag potential threats.
- Identify brute-force attacks by monitoring failed login attempts
- Detect ransomware by observing rapid file encryption patterns
- Spot data exfiltration through unusual network connections
For instance, if a server that typically sends 100 MB of data per hour suddenly transmits 50 GB, it could indicate a data breach. A system monitor with anomaly detection can alert security teams in real time.
Log Monitoring and Correlation
Logs are a goldmine of security information. A system monitor that aggregates and analyzes logs from multiple sources—servers, firewalls, applications—can uncover attack patterns that would otherwise go unnoticed.
- Centralized log collection and normalization
- Real-time correlation of events across systems
- Integration with SIEM tools like Splunk or IBM QRadar
For example, a failed login on a web server followed by a successful login from a different IP address minutes later could indicate credential stuffing. By correlating these events, a system monitor helps security teams respond faster.
“The best defense is a good offense—and continuous monitoring is your first line of defense.”
Best Practices for Implementing a System Monitor
Deploying a system monitor is not just about installing software—it requires careful planning, configuration, and ongoing management. Following best practices ensures you get the most value from your monitoring investment.
Define Clear Monitoring Objectives
Before deploying any system monitor, define what you want to achieve. Are you focused on uptime, performance optimization, security, or compliance? Your goals will determine which metrics to track, how frequently to collect data, and how to configure alerts.
- Identify critical systems and applications
- Set service level objectives (SLOs) for availability and performance
- Document escalation procedures for different alert levels
For example, a financial institution might prioritize transaction processing speed and data integrity, while a media company might focus on content delivery performance.
Start Small and Scale Gradually
It’s tempting to monitor everything at once, but this can lead to alert fatigue and data overload. Begin with a pilot project—monitor a few critical servers or applications—and refine your approach before expanding.
- Use templates and automation to standardize configurations
- Train your team on interpreting alerts and dashboards
- Regularly review and tune alert thresholds to reduce false positives
This phased approach allows you to build expertise and confidence while minimizing disruption.
Ensure High Availability of the Monitoring System
Ironically, many organizations overlook the availability of their monitoring system itself. If the system monitor goes down, you lose visibility into your entire infrastructure.
- Deploy redundant monitoring servers in different locations
- Use heartbeat checks to monitor the monitor
- Store data in resilient storage systems with backups
Some tools, like Zabbix and Nagios, support high-availability configurations to prevent single points of failure.
System Monitor in Cloud and Hybrid Environments
With the rise of cloud computing, traditional monitoring approaches are no longer sufficient. Cloud environments are dynamic, ephemeral, and often multi-cloud, requiring a more flexible and automated system monitor.
Challenges of Monitoring Cloud Infrastructure
Cloud resources can be created, scaled, and destroyed in seconds. This elasticity makes it difficult to maintain consistent monitoring coverage. Traditional tools that rely on static IP addresses or manual configuration struggle in such environments.
- Auto-scaling groups can spin up new instances without notification
- Short-lived containers may exist for only minutes
- Different cloud providers have unique APIs and metrics
To address these challenges, modern system monitors use auto-discovery, tag-based filtering, and cloud-native integrations. For example, Datadog and New Relic can automatically detect new EC2 instances in AWS and start monitoring them within seconds.
Hybrid and Multi-Cloud Monitoring Strategies
Many organizations operate in hybrid environments—combining on-premises data centers with public clouds. A unified system monitor that can span these environments is essential for consistent visibility.
- Use agents that work across platforms (e.g., Linux, Windows, Kubernetes)
- Aggregate metrics from multiple cloud providers into a single dashboard
- Apply consistent alerting policies across all environments
Tools like Prometheus with Thanos, or commercial platforms like Datadog, excel in this space by offering unified observability across hybrid infrastructures.
Future Trends in System Monitoring
The field of system monitoring is evolving rapidly, driven by advances in AI, cloud computing, and distributed systems. Staying ahead of these trends ensures your monitoring strategy remains effective and future-proof.
AI and Machine Learning in Monitoring
Artificial intelligence is transforming system monitoring from reactive to predictive. Instead of waiting for thresholds to be breached, AI-powered tools can forecast issues based on historical patterns.
- Predict server failures before they occur
- Automatically classify and prioritize alerts
- Identify performance bottlenecks using root cause analysis
For example, Google’s SRE team uses machine learning to detect anomalies in service metrics, reducing mean time to detection (MTTD) significantly.
Observability vs. Monitoring: The Shift in Mindset
While traditional monitoring focuses on predefined metrics, observability emphasizes understanding system behavior through logs, metrics, and traces. It’s about asking questions you didn’t know to ask.
- Observability enables deeper debugging of complex systems
- It supports microservices and serverless architectures
- Tools like OpenTelemetry are standardizing data collection
The future belongs to observability platforms that combine monitoring, tracing, and logging into a single, cohesive experience.
What is a system monitor used for?
A system monitor is used to track the performance, availability, and health of IT systems, including servers, networks, and applications. It helps detect issues early, optimize resource usage, ensure security, and maintain service reliability.
Is there a free system monitor tool available?
Yes, several free system monitor tools are available, including Nagios Core, Zabbix, and Prometheus. These open-source solutions offer robust monitoring capabilities and are widely used in both small and large organizations.
Can a system monitor improve cybersecurity?
Yes, a system monitor can significantly improve cybersecurity by detecting unusual behavior, monitoring logs for suspicious activity, and providing real-time alerts on potential threats like brute-force attacks or data exfiltration.
How does a system monitor work in the cloud?
In the cloud, a system monitor uses APIs and agents to collect metrics from virtual machines, containers, and managed services. It supports auto-discovery, dynamic scaling, and integration with cloud-native tools like AWS CloudWatch or Google Cloud Operations.
What’s the difference between monitoring and observability?
Monitoring checks predefined metrics against thresholds, while observability allows you to explore system behavior dynamically using logs, metrics, and traces. Observability is more suited for complex, distributed systems where issues are not easily predictable.
In conclusion, a system monitor is no longer a luxury—it’s a necessity for any organization relying on digital infrastructure. From preventing downtime to enhancing security and optimizing performance, the right monitoring strategy can deliver significant business value. Whether you choose an open-source powerhouse like Zabbix or a cloud-native platform like Datadog, the key is to implement it thoughtfully, align it with your goals, and evolve it as your environment grows. The future of system monitoring is intelligent, automated, and deeply integrated—embrace it to stay ahead in the digital race.
Recommended for you 👇
Further Reading: