Ever experienced a sudden crash, blackout, or complete breakdown of a critical process? That’s system failure in action—silent, sudden, and often devastating. From power grids to software networks, no system is immune. Let’s dive deep into what really goes wrong—and how to stop it before it’s too late.





What Is System Failure? A Clear Definition

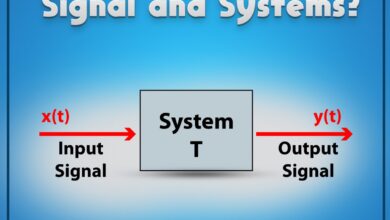
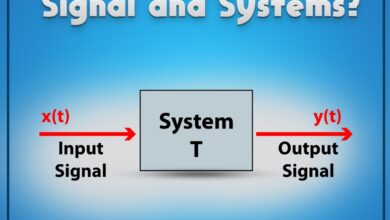
At its core, a system failure occurs when a system—be it mechanical, digital, organizational, or biological—ceases to perform its intended function. This can range from a minor glitch to a catastrophic collapse. Understanding this concept is the first step toward prevention.
The Anatomy of a System
Every system consists of interconnected components working together to achieve a goal. These components may include hardware, software, human operators, data flows, and environmental inputs. When one part fails, it can trigger a chain reaction.
- Input mechanisms (e.g., sensors, user interfaces)
- Processing units (e.g., CPUs, decision-makers)
- Output channels (e.g., displays, actuators)
- Feedback loops for self-regulation
When any of these elements malfunction, the entire system is at risk.
Types of System Failure
Not all system failures are the same. They can be categorized based on cause, scope, and impact:
- Partial failure: Only a segment of the system stops working (e.g., a single server in a cluster).
- Total failure: The entire system collapses (e.g., a nationwide blackout).
- Latent failure: A hidden flaw that remains undetected until triggered (e.g., a software bug).
- Active failure: An immediate error caused by human action or component breakdown.
“Failures are not random events; they are the result of systems that are poorly designed, poorly maintained, or poorly understood.” — Sidney Dekker, safety expert
Common Causes of System Failure
Understanding the root causes of system failure is essential for building resilient infrastructures. While each incident is unique, certain patterns emerge across industries and technologies.
Hardware Malfunctions
Physical components degrade over time. Hard drives crash, circuits overheat, and mechanical parts wear out. In data centers, a single failing server can cascade into a larger outage if redundancy isn’t in place.
For example, in 2017, an Amazon Web Services (AWS) S3 storage outage was triggered by a typo during a routine debugging task, but the underlying issue was inadequate safeguards against human error on critical systems. AWS S3 Outage Report
- Overheating due to poor ventilation
- Power surges damaging circuitry
- Manufacturing defects in components
Software Bugs and Glitches
Code is written by humans—and humans make mistakes. A single line of faulty code can bring down an entire application. The 1999 Mars Climate Orbiter disaster, which cost $327 million, was caused by a unit mismatch between metric and imperial systems in the navigation software.
Such bugs often go undetected during testing, especially in complex, distributed systems. Modern software development practices like continuous integration and automated testing aim to reduce these risks, but they’re not foolproof.
- Memory leaks consuming system resources
- Null pointer exceptions crashing applications
- Insecure code leading to exploits
Human Error
One of the most common—and underestimated—causes of system failure is human error. This includes misconfigurations, incorrect data entry, and poor decision-making under pressure.
A 2021 report by IBM found that human error was responsible for 23% of all data breaches. In industrial settings, operators may bypass safety protocols to save time, increasing the risk of catastrophic failure.
- Accidental deletion of critical files
- Incorrect system configuration
- Failure to follow standard operating procedures
System Failure in Critical Infrastructure
When system failure strikes essential services like power, water, or transportation, the consequences can be life-threatening. These systems are complex, interdependent, and often operate under tight margins.
Power Grid Failures
Electricity grids are among the most complex engineered systems on Earth. A failure in one region can cascade across continents. The 2003 Northeast Blackout affected over 50 million people in the U.S. and Canada due to a software bug in an Ohio-based energy company’s monitoring system.
The root cause was a combination of inadequate system monitoring, poor communication, and lack of real-time data. Since then, grid operators have invested heavily in smart grid technologies and automated fail-safes.
- Cascading failures due to overload
- Vulnerability to cyberattacks
- Aging infrastructure in developed nations
Water Supply System Breakdowns
Water treatment and distribution systems rely on pumps, sensors, and chemical controls. A failure in any of these can lead to contamination or service disruption. In 2021, a cyberattack on a Florida water treatment plant nearly poisoned the supply by increasing sodium hydroxide levels.
This incident highlighted the vulnerability of industrial control systems (ICS) to remote attacks. Many of these systems were never designed with cybersecurity in mind.
- Chemical dosing errors
- Pump failures during peak demand
- Contamination from breached pipelines
Transportation Network Disruptions
From air traffic control to railway signaling, transportation systems depend on precise coordination. A single system failure can ground flights, halt trains, or cause accidents.
In 2015, a software glitch in the U.S. Federal Aviation Administration’s (FAA) Notice to Airmen (NOTAM) system caused a nationwide ground stop, stranding thousands of passengers. The system had no backup, and recovery took hours.
- Signal failures in rail networks
- GPS spoofing in aviation
- Traffic management system crashes
Digital and IT System Failures
In the digital age, system failure often means data loss, service downtime, or security breaches. Companies rely on IT systems for everything from customer service to financial transactions.
Cloud Service Outages
Cloud computing has revolutionized business operations, but it also introduces new risks. When a major provider like AWS, Google Cloud, or Microsoft Azure goes down, thousands of businesses are affected.
The 2021 AWS outage disrupted services like Slack, Netflix, and Robinhood. The cause? A configuration error in the network’s load balancers. Despite redundancy, the failure spread because of interdependencies between services.
- Region-wide service degradation
- Data replication failures
- API gateway crashes
Data Center Failures
Data centers are the backbone of the internet. A failure here can mean lost revenue, damaged reputation, and legal consequences. Common issues include cooling system failures, power outages, and fire suppression malfunctions.
In 2019, a fire at a data center in Strasbourg, France, took down millions of websites hosted by OVHcloud. The company lost three buildings, and some clients never recovered their data.
- Fire or flood damage
- Power supply interruptions
- Network backbone disconnections
Cybersecurity Breaches as System Failure
Cyberattacks are no longer just about stealing data—they can cripple entire systems. Ransomware, distributed denial-of-service (DDoS) attacks, and zero-day exploits can all trigger system failure.
The 2017 WannaCry ransomware attack affected over 200,000 computers in 150 countries, including hospitals in the UK’s National Health Service (NHS). Critical systems were locked, surgeries were canceled, and lives were put at risk.
- Ransomware encrypting critical systems
- DDoS overwhelming server capacity
- Insider threats bypassing security
Organizational and Management System Failures
Not all system failures are technical. Often, the root cause lies in poor leadership, flawed processes, or cultural issues within an organization.
Poor Communication and Coordination
When teams don’t communicate effectively, errors go unnoticed. In the 1986 Challenger space shuttle disaster, engineers had warned about O-ring failure in cold weather, but their concerns were not properly escalated.
This was not a technical failure alone—it was a failure of organizational communication. Information existed, but it didn’t reach decision-makers in time.
- Silos between departments
- Lack of incident reporting culture
- Inadequate handover procedures
Inadequate Training and Procedures
Even the best systems fail when people don’t know how to use them. Inadequate training leads to mistakes, especially during emergencies when stress is high.
A 2018 study by the National Institute of Standards and Technology (NIST) found that 85% of cybersecurity incidents could have been mitigated with better employee training.
- Unclear emergency protocols
- Lack of simulation drills
- Outdated operating manuals
Failure to Learn from Past Mistakes
Organizations often repeat the same errors because they don’t conduct proper post-mortems or implement corrective actions. After a system failure, it’s crucial to analyze what went wrong and update policies accordingly.
The Deepwater Horizon oil spill in 2010 was preceded by multiple warning signs and near-misses that were ignored. A culture of complacency and cost-cutting contributed to the disaster.
- No formal incident review process
- Blame-focused rather than learning-focused culture
- Failure to update risk assessments
Biological and Natural System Failures
System failure isn’t limited to machines and organizations. Ecosystems, human bodies, and natural processes can also fail—sometimes with irreversible consequences.
Ecosystem Collapse
When a natural system like a coral reef or rainforest reaches a tipping point, it can collapse rapidly. Overfishing, pollution, and climate change are pushing many ecosystems toward failure.
The Great Barrier Reef has lost over 50% of its coral cover since 1985 due to rising sea temperatures and ocean acidification. Once a reef dies, recovery can take centuries—if it happens at all.
- Biodiversity loss
- Trophic cascade effects
- Altered climate regulation
Human Body System Failure
The human body is a complex biological system. Organ failure—such as heart, kidney, or respiratory failure—can be caused by disease, trauma, or aging.
For example, septic shock is a systemic failure triggered by infection, where the immune response spirals out of control, leading to multiple organ failure. Early detection and intervention are critical.
- Cardiovascular system collapse
- Neurological system breakdown
- Immune system overreaction
Natural Disasters as System Stressors
Earthquakes, hurricanes, and wildfires can overwhelm both natural and human-made systems. These events don’t cause failure directly but expose existing vulnerabilities.
Hurricane Katrina in 2005 revealed the fragility of New Orleans’ levee system and emergency response infrastructure. Poor planning and maintenance turned a natural disaster into a human catastrophe.
- Infrastructure not built to withstand extreme events
- Lack of evacuation plans
- Overloaded emergency services
How to Prevent System Failure: Best Practices
While no system can be 100% failure-proof, risk can be significantly reduced through proactive design, monitoring, and culture.
Redundancy and Fail-Safe Design
Redundancy means having backup components that take over when the primary ones fail. This is common in aviation, where multiple flight control systems operate in parallel.
Fail-safe design ensures that when a failure occurs, the system defaults to a safe state. For example, elevators have brakes that engage automatically if the cable breaks.
- Duplicate servers in data centers
- Backup power generators
- Automatic shutdown mechanisms
Regular Maintenance and Monitoring
Preventive maintenance catches issues before they escalate. Sensors and monitoring tools can detect anomalies in real time, allowing for early intervention.
Industrial IoT (Internet of Things) devices now enable predictive maintenance by analyzing vibration, temperature, and performance data to forecast failures.
- Scheduled hardware inspections
- Software patching and updates
- Real-time performance dashboards
Robust Testing and Simulation
Stress-testing systems under extreme conditions reveals weaknesses. Fire drills, penetration testing, and disaster recovery simulations prepare organizations for real failures.
Netflix’s Chaos Monkey tool randomly disables parts of its production system to ensure resilience. This “chaos engineering” approach builds confidence in system stability.
- Load testing for web applications
- Disaster recovery drills
- Red team/blue team cybersecurity exercises
The Future of System Resilience
As systems grow more complex and interconnected, the risk of failure evolves. Emerging technologies like AI, quantum computing, and decentralized networks offer both opportunities and challenges.
AI and Machine Learning in Failure Prediction
AI can analyze vast datasets to predict failures before they happen. For example, AI models can forecast equipment breakdowns in manufacturing plants based on sensor data.
However, AI systems themselves can fail—due to biased training data, overfitting, or adversarial attacks. Ensuring AI reliability is a growing field of research.
- Predictive maintenance using AI
- Anomaly detection in network traffic
- Autonomous system recovery protocols
Decentralized Systems and Blockchain
Decentralized architectures, like blockchain, reduce single points of failure. Instead of relying on one central server, data is distributed across many nodes.
While not immune to failure, these systems are more resilient to attacks and outages. However, they face challenges in scalability and energy consumption.
- Distributed ledger technology for secure records
- Peer-to-peer networks for communication
- Smart contracts with automated execution
Building a Culture of Resilience
Technology alone isn’t enough. Organizations must foster a culture where safety, transparency, and continuous improvement are prioritized.
High-Reliability Organizations (HROs), like nuclear power plants and air traffic control, emphasize mindfulness, deference to expertise, and preoccupation with failure.
- Encouraging reporting of near-misses
- Leadership commitment to safety
- Learning from small failures to prevent big ones
What is a system failure?
A system failure occurs when a system—technical, organizational, or biological—stops performing its intended function, either partially or completely.
What are the most common causes of system failure?
The most common causes include hardware malfunctions, software bugs, human error, cyberattacks, poor communication, and natural disasters.
How can system failure be prevented?
Prevention strategies include redundancy, regular maintenance, robust testing, real-time monitoring, and fostering a safety-focused organizational culture.
Can AI prevent system failure?
Yes, AI can help predict and mitigate failures through pattern recognition and automation, but AI systems themselves must be carefully designed to avoid new failure modes.
What was a major real-world example of system failure?
The 2003 Northeast Blackout, caused by a software bug and poor monitoring, affected 50 million people and highlighted the fragility of power grids.
System failure is not just a technical issue—it’s a systemic one. Whether in machines, organizations, or nature, failures reveal weaknesses in design, communication, and preparedness. By understanding the causes, learning from past mistakes, and investing in resilience, we can build systems that don’t just survive—but thrive—under pressure. The goal isn’t to eliminate failure entirely (which is impossible), but to minimize its impact and accelerate recovery. In an increasingly interconnected world, that’s not just smart engineering—it’s essential for survival.
Further Reading: